Перевод доклада
Exploring Java
Hidden Costs Джейка Уортона (Jake Wharton).
Транскрипция взята с
realm.io.
[Примечания переводчика написаны курсивом в квадратных скобках.]
В Android понемногу появляется поддержка Java 8, и важно помнить, что любые языковые и библиотечные возможности имеют свою цену. Хоть устройства и становятся быстрее и имеют больше памяти, проблемы производительности и объёма кода всё ещё остаются актуальными. Эта презентация — обзор скрытых издержек, связанных с языковыми возможностями Java. Мы сосредоточимся на оптимизациях, актуальных для разработчиков библиотек и приложений, а также на инструментах, которые помогут измерить воздействие этих оптимизаций.
Введение
Сейчас я расскажу о том, за чем наблюдаю последние полгода. Поначалу может быть непонятно, как и зачем оптимизировать код из моих примеров. Но подождите до конца, я поделюсь несколькими конкретными фишечками, которые помогут вам избегать всего того, что вы сейчас увидите. Ещё я буду использовать много инструментов в терминале; в конце будут ссылки на них.
Dex-файлы
Мы начнём с вопроса, на который есть несколько вариантов ответа. Сколько методов в этом коде? Ноль, один или два?
class Example {
}
Возможно, у вас уже сработала интуиция. Давайте посмотрим и подумаем, как можно ответить на этот вопрос. Прежде всего, внутри класса нет методов. Я не писал методы в исходнике, потому так вполне можно сказать. Но, разумеется, это был бы совершенно неинтересный ответ. Давайте пропустим наш класс через все этапы сборки Android-приложения и посмотрим, что получается:
$ echo "class Example {
}" > Example.java
$ javac Example.java
$ javap Example.class
class Example {
Example();
}
Мы записываем код в файл, потом запускаем на нём компилятор Java, чтобы превратить исходник в class-файл. Потом используем другой инструмент из JDK, который называется javap. Это позволит нам заглянуть в файл класса и увидеть, во что скомпилировался исходник. Если javap запустить на нашем скомпилированном классе, мы увидим, что внутри нашего класса Example есть конструктор. Мы не писали его в исходном коде, его добавил javac. Это значит, что в файле исходника нет методов, но есть один метод в классе. Но на этом сборка Android-приложения не прекращается.

В Android SDK есть инструмент dx, который дексит class-файлы, то есть конвертирует их в байт-код Dalvik, используемый в Android. Мы можем пропустить наш класс Example через dx, а с помощью другого инструмента Android SDK под названием dexdump узнаем о том, что находится внутри полученного dex-файла. Если его запустить, он пройдётся по определённым адресам в файле, пересчитает его различные таблицы и выдаст нам всю эту информацию. Если присмотреться, можно заметить одну интересную вещь – объём таблицы методов dex-файла:
$ dx --dex --output=example.dex Example.class $ dexdump -f example.dex method_ids_size : 2
Она говорит, что в нашем классе два метода. Это не особо информативно. К сожалению, нет простого способа узнать с помощью dexdump, что это за методы. Поэтому я написал небольшой инструмент для получения списка методов из dex-файла. Если его запустить, увидим эти два метода:
$ dex-method-list example.dex Example <init>() java.lang.Object <init>()
Возвращается наш конструктор, который, как мы знаем, создал компилятор Java, хотя явно мы его не писали. Но также выводится конструктор класса Object. Конечно, наш код нигде не выполняет new Object(), но тогда откуда появляется этот метод, на который есть ссылка в dex-файле? Сейчас я добавлю флаг -c к javap, чтобы декомпилировать байт-код в удобочитаемые инструкции.
$ javap -c Example.class
class Example {
Example();
Code:
0: aload_0
1: invokespecial #1 //java/lang/Object."<init>":()V
4: return
}
В строке «1» нашего сгенерированного конструктора находится вызов конструктора суперкласса. Так происходит, потому что класс Example, у которого явно не задан суперкласс, наследует Object. Каждый конструктор должен вызвать конструктор суперкласса. Вызов конструктора суперкласса вставляется автоматически. В результате в нашем классе суммарно упоминается два метода.

Все ответы на мой вопрос были правильными. Разница лишь в терминологии. Как авторы исходного кода мы не объявили ни одного метода. Но два других ответа более важны для нас, так как нас волнует результат, который получается из этих исходников — методы, которые действительно оказываются в файлах классов после компиляции, будучи объявленными хоть явно, хоть неявно.
Итого в dex-файле упомянуто два метода, включая тот, который мы (неявно) объявили, и тот, на который сослались из своих методов. Например, метод Log.d, который все мы порой вызываем, тоже учитывается в списке методов dex-файла. На это часто ссылаются, когда говорят о количестве методов в Android, потому что в dex оно ограничено.
Мы увидели, что у класса есть конструктор, хоть мы его и не объявляли, поэтому давайте поищем другие скрытые штуки, о создании которых мы могли и не знать.
Вложенные классы – это полезная конструкция:
// Outer.java
public class Outer {
private class Example {
}
}Их нет в Java 1.0. Они появились в более поздней версии. Подобный код получается, когда объявляешь адаптер внутри view или презентера:
// ItemsView.java
public class ItemsView {
private class ItemsAdapter {
}
}$ javac ItemsView.java $ ls ItemsView.class ItemsView.java ItemsView$ItemsAdapter.class
В этом файле объявлено два класса, один вложен в другой. Если мы это скомпилируем, то получим два разных class-файла. Если бы в Java были по-настоящему вложенные классы, мы бы получили только один class-файл. Был бы только ItemsView.class. Но в Java нет настоящего вложения, так что же в этих классах? В ItemsView, во внешнем классе, есть только конструктор. Нет упоминаний, нет намёков на то, что был вложенный класс:
$ javap ItemsView
class ItemsView {
ItemsView();
}
Если мы посмотрим на содержимое внутреннего класса, то увидим, что у него есть неявный конструктор; также можно заметить, что в имени упоминается внешний класс.
$ javap 'ItemsView$ItemsAdapter'
class ItemsView$ItemsAdapter {
ItemsView$ItemsAdapter();
}
Стоит обратить внимание на ещё одну важную вещь: мы видим, что класс ItemsView является публичным (public), как мы и объявили в исходнике. Но внутренний класс, вложенный класс, хотя и объявлен приватным (private), не является приватным в скомпилированном классе. Он доступен в пределах пакета. Это логично, ведь оба наших класса лежат в одном пакете. И это опять подтверждает, что в Java на самом деле нет вложенных классов.
// ItemsView.java
public class ItemsView {
}
// ItemsAdapter.java
class ItemsAdapter {
}Если определение одного класса находится внутри другого, фактически создаётся два класса, лежащих рядом, в одном пакете. При желании можно назвать два отдельных класса так, как если бы они были вложены:
// ItemsView.java
public class ItemsView {
}
// ItemsView$ItemsAdapter.java
class ItemsView$ItemsAdapter {
}Символ доллара – это корректный идентификатор в Java. Он вставляется компилятором между именем внешнего и вложенного класса.
// ItemsView.java
public class ItemsView {
private static String displayText(String item) {
return ""; // TODO
}
private class ItemsAdapter {
}
}Однако, интересный нюанс заключается в том, что я могу вызвать приватный метод внешнего класса из вложенного. Мы знаем, что в Java нет по-настоящему вложенных классов, но давайте проверим, как это работает в нашей гипотетической системе, где класс ItemsAdapter должен вызвать приватный метод класса ItemsView. Этот код просто-напросто не скомпилируется:
// ItemsView.java
public class ItemsView {
private static String displayText(String item) {
return ""; // TODO
}
}
// ItemsView$ItemsAdapter.java
class ItemsView$ItemsAdapter {
void bindItem(TextView tv, String item) {
tv.setText(ItemsView.displayText(item));
}
}Тем не менее, вот это скомпилируется:
// ItemsView.java
public class ItemsView {
private static String displayText(String item) {
return ""; // TODO
}
private class ItemsAdapter {
void bindItem(TextView tv, String item) {
tv.setText(ItemsView.displayText(item));
}
}
}Что же здесь происходит? Скомпилируем и декомпилируем:
$ javac -bootclasspath android-sdk/platforms/android-24/android.jar \
ItemsView.java
Я упоминаю класс TextView, поэтому добавил API Android’а при компиляции. Теперь я покажу содержимое вложенного класса, чтобы посмотреть, какой метод был вызван.
$ javap -c 'ItemsView$ItemsAdapter'
class ItemsView$ItemAdapter {
void bindItem(android.widget.TextView, java.lang.String);
Code:
0: aload_1
1: aload_2
2: invokestatic #3 // Method ItemsView.access$000:…
5: invokevirtual #4 // Method TextView.setText:…
8: return
}
Если посмотреть на строку «2», там не вызывается метод displayText. Там вызывается access$000, который мы не объявляли. Найдём ли мы его в классе ItemsView?
$ javap -p ItemsView
class ItemsView {
ItemsView();
private static java.lang.String displayText(…);
static java.lang.String access$000(…);
}
Видно, что наш приватный статический метод есть, но также автоматически добавился метод, который мы не писали.
$ javap -p -c ItemsView
class ItemsView {
ItemsView();
Code: <removed>
private static java.lang.String displayText(…);
Code: <removed>
static java.lang.String access$000(…);
Code:
0: aload_0
1: invokestatic #1 // Method displayText:…
4: areturn
}
Если посмотреть на код этого метода, увидим, что он просто вызывает наш метод displayText. Так происходит, потому что нам нужен способ вызвать приватный метод из контекста пакета. Java генерирует синтетический метод, видимый в пределах пакета, чтобы позволить вызывать наш метод.
Если вернуться к нашему примеру с двумя разными файлами, мы можем скомпилировать это таким же точно образом. Мы добавим этот метод и изменим код так, чтобы он вызывал этот метод.
// ItemsView.java
public class ItemsView {
private static String displayText(String item) {
return ""; // TODO
}
static String access$000(String item) {
return displayText(item);
}
}
// ItemsView$ItemsAdapter.java
class ItemsView$ItemsAdapter {
void bindItem(TextView tv, String item) {
tv.setText(ItemsView.access$000(item));
}
}[Классы из двух файлов исходников на самом деле имеют небольшое отличие от вложенных классов из одного исходника: в Java-байткоде есть модификатор synthetic, который компилятор применяет к синтетическим методам, но в языке он отсутствует, и вручную его применить нельзя.]
В одном dex-файле может находиться ограниченное число методов, и нужно учитывать ситуации, в которых компиятор добавляет лишних методов в код. Важно понимать, что это происходит, потому что вы пытаетесь получить доступ к приватному члену там, где сделать это прямым путём нельзя.
Ближе к Dex
Вы можете сказать: «Ну, ты скомпилировал код Java-компилятором. Может, dx уберёт эти лишние методы?»
Если мы скомпилируем эти два файла в dex и посмотрим в список методов, увидим, что нифига подобного. dx компилирует всё, как есть. Синтетические методы попадают в наши dex-файлы.
$ dx --dex --output=example.dex *.class
$ dex-method-list example.dex
ItemsView <init>()
ItemsView access$000(String) → String
ItemsView displayText(String) → String
ItemsView$ItemsAdapter <init>(ItemsView)
ItemsView$ItemsAdapter bindItem(TextView, String)
android.widget.TextView setText(CharSequence)
java.lang.Object <init>()
Вы можете сказать: «Ну, я слышал про компилятор Jack. И Jack работает непосредственно с исходниками и самостоятельно генерирует dex-файлы, так что, может быть, он не создаёт лишнего метода».
$ java -jar android-sdk/build-tools/24.0.1/jack.jar \
-cp android-sdk/platforms/android-24/android.jar \
--output-dex . \
ItemsView.java
$ dex-method-list classes.dex
ItemsView -wrap0(String) → String
ItemsView <init>()
ItemsView displayText(String) → String
ItemsView$ItemsAdapter <init>(ItemsView)
ItemsView$ItemsAdapter bindItem(TextView, String)
android.widget.TextView setText(CharSequence)
java.lang.Object <init>()
Да, там таки нет метода access$000. Однако, есть метод -wrap0, и по сути это то же самое.
Многие используют ProGuard. Вы можете сказать: «Ну, ProGuard ведь займётся этим, правда?» Я по-быстрому добавлю ProGuard, обработаю им классы и выведу список методов. Вот что получится:
$ echo "-dontobfuscate
-keep class ItemsView$ItemsAdapter { void bindItem(...); }
" > rules.txt
$ java -jar proguard-base-5.2.1.jar \
-include rules.txt \
-injars . \
-outjars example-proguard.jar \
-libraryjars android-sdk/platforms/android-24/android.jar
$ dex-method-list example-proguard.jar
ItemsView access$000(String) → String
ItemsView$ItemsAdapter bindItem(TextView, String)
android.widget.TextView setText(CharSequence)
Конструкторы удалились, потому что не использовались. Я оставлю их, потому что, по-хорошему, они понадобятся.
$ dex-method-list example-proguard.jar ItemsView <init>() ItemsView access$000(String) → String ItemsView$ItemsAdapter <init>(ItemsView) ItemsView$ItemsAdapter bindItem(TextView, String) android.widget.TextView setText(CharSequence) java.lang.Object <init>()
Ну вот, синтетический аксессор остался. Но, если присмотреться ближе, увидим, что исчез метод displayText. Что, блин, произошло? Разархивируем jar, который нам создал ProGuard, и декомпилируем классы, им обработанные:
$ unzip example-proguard.jar
$ javap -c ItemsView
public final class ItemsView {
static java.lang.String access$000(java.lang.String);
Code:
0: ldc #1 // String ""
2: areturn
}
Метод теперь не вызвает displayText. ProGuard переместил код из метода displayText в синтетический аксессор, удалив исходный метод. access$000 был единственным методом, который вызывал displayText, поэтому код последнего был просто встроен в первый, потому что больше нигде не нужен. Да, ProGuard может помочь. Но нет гарантии, что у него это получится. Нам повезло, потому что пример очень простой, но в сложном классе может получиться иначе. Вы можете подумать: «Ну, я использую не так много вложенных классов. Я получу не так уж много синтетических методов, правда?»
Анонимный класс
Вспомним об анонимных классах:
class MyActivity extends Activity {
@Override protected void onCreate(Bundle state) {
super.onCreate(state);
setContentView(R.layout.whatever);
findViewById(R.id.button).setOnClickListener(
new OnClickListener() {
@Override public void onClick(View view) {
// Hello!
}
});
}
}Анонимные классы ведут себя точно так же. Это те же вложенные классы, просто у них нет имени. Все мы постоянно пользуемся OnClickListener’ами, а ведь если из них использовать приватные методы внешнего класса, будут генерироваться такие же синтетические аксессоры.
class MyActivity extends Activity {
@Override protected void onCreate(Bundle state) {
super.onCreate(state);
setContentView(R.layout.whatever);
findViewById(R.id.button).setOnClickListener(
new OnClickListener() {
@Override public void onClick(View view) {
doSomething();
}
});
}
private void doSomething() {
// ...
}
}Это правило также действует для полей:
class MyActivity extends Activity {
private int count;
@Override protected void onCreate(Bundle state) {
super.onCreate(state);
setContentView(R.layout.whatever);
findViewById(R.id.button).setOnClickListener(
new OnClickListener() {
@Override public void onClick(View view) {
count = 0;
++count;
--count;
count++;
count--;
Log.d("Count", "= " + count);
}
});
}
}Думаю, такая ситуация обыденна. Во внешнем классе есть поля, внутри слушателей мы меняем состояние активити. Здесь я написал абсолютно ужасный код, хотя я всего лишь меняю значение поля. Здесь есть [присваивание,] пре-инкремент, пре-декремент, пост-инкремент, пост-декремент, а затем, чтобы бросить значение поля в логи, оно просто считывается. Сколько методов здесь получится? Может, два, один для чтения, другой – для записи? Посмотрим:
$ javac -bootclasspath android-sdk/platforms/android-24/android.jar \
MyActivity.java
$ javap MyActivity
class MyActivity extends android.app.Activity {
MyActivity();
protected void onCreate(android.os.Bundle);
static int access$002(MyActivity, int); // count = 0 write
static int access$004(MyActivity); // ++count preinc
static int access$006(MyActivity); // --count predec
static int access$008(MyActivity); // count++ postinc
static int access$010(MyActivity); // count-- postdec
static int access$000(MyActivity); // count read
}
Компилятор генерирует по методу на каждое действие. Так что если в активити или фрагменте находится подобный код, в котором четыре-пять слушателей и, скажем, десяток полей во внешнем классе, получается нехилая куча синтетических аксессоров. Вы можете до сих пор считать, что проблема незначительна. «Ну, может, их 50 или 100. Имеет ли это значение?» Вот и проверим.
В естественной среде
Можно выяснить, как много синтетических аксессоров обитает на вашем устройстве. Этот скрипт сольёт все APK с вашего телефона. Каждое установленное приложение.
$ adb shell mkdir /mnt/sdcard/apks $ adb shell cmd package list packages -3 -f \ | cut -c 9- \ | sed 's|=| /mnt/sdcard/apks/|' \ | xargs -t -L1 adb shell cp $ adb pull /mnt/sdcard/apks
Мы напишем скрипт, который перебирает все методы в индексе dex и подсчитывает объёмы синтетики среди них:
#!/bin/bash accessors.sh
set -e
METHODS=$(dex-method-list $1 | \grep 'access\$')
ACCESSORS=$(echo "$METHODS" | wc -l | xargs)
METHOD_AND_READ=$(echo "$METHODS" | egrep 'access\$\d+00\(' | wc -l | xargs)
WRITE=$(echo "$METHODS" | egrep 'access\$\d+02\(' | wc -l | xargs)
PREINC=$(echo "$METHODS" | egrep 'access\$\d+04\(' | wc -l | xargs)
PREDEC=$(echo "$METHODS" | egrep 'access\$\d+06\(' | wc -l | xargs)
POSTINC=$(echo "$METHODS" | egrep 'access\$\d+08\(' | wc -l | xargs)
POSTDEC=$(echo "$METHODS" | egrep 'access\$\d+10\(' | wc -l | xargs)
OTHER=$(($ACCESSORS - $METHOD_AND_READ - $WRITE - $PREINC - $PREDEC - $POSTINC - $POSTDEC))
NAME=$(basename $1)
echo -e "$NAME\t$ACCESSORS\t$READ\t$WRITE\t$PREINC\t$PREDEC\t$POSTINC\t$POSTDEC\t$OTHER"
Потом запустим эту бешеную команду, которая пройдёт по всем APK в моём телефоне, запустим этот скрипт и сформируем таблицу:

Вот полученная таблица, отсортированная по количеству синтетических методов. В моём телефоне их много тысяч. Amazon занимает пять мест из шести первых [на самом деле – четыре]. У пары первых приложений по 5 000 синтетических аксессоров. Пять тысяч методов! Это тянет на целую библиотеку! Это дохрена. Просто дохренища бесполезных методов, которые нужны только для вызова других методов.
ProGuard, обфусцируя методы и встраивая их код, борется с этим, поэтому не стоит принимать эти числа за точные. Это лишь приблизительное количество, показывающее, сколько методов было скомпилировано. Кстати, Twitter внизу. У них тысяча синтетических аксессоров. Они обрабатывают приложения ProGuard'ом, так что, вероятно, их было больше. Но я думаю, что это интересный результат, потому что у них самое малое количество синтетических аксессоров для наибольшего количества методов. Всего в приложении 171 000 методов, из которых 1 000 — синтетические аксессоры. Впечатляюще.
Можно это исправить. Это просто, ничего секретного. Нужно сделать поля и методы, к которым происходят обращения из вложенных классов, package-private. В IntelliJ IDEA [Android Studio — это та же самая IDE] есть инспекция для этого. Изначально она отключена, но можно найти и включить её.
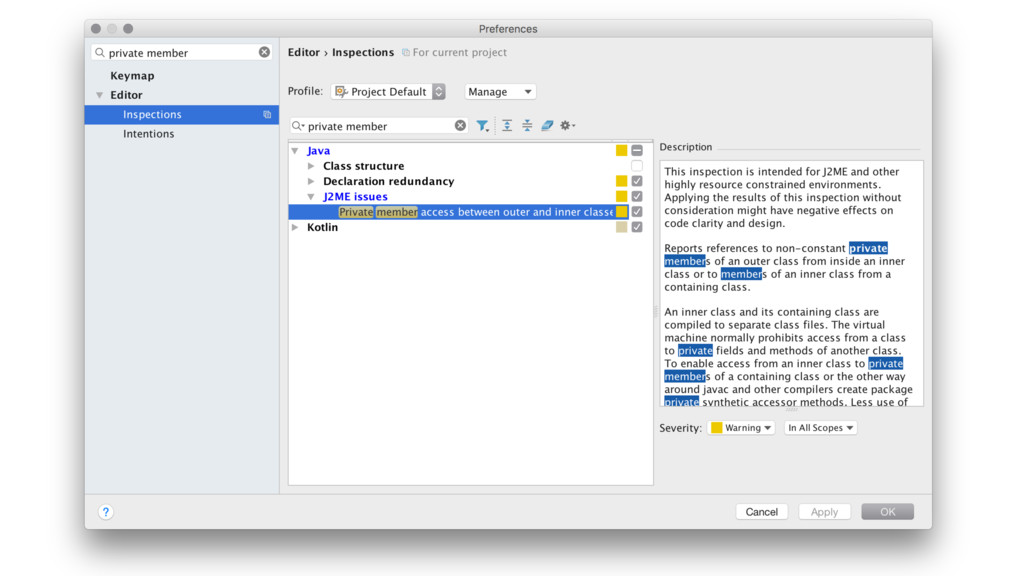
Теперь, если взять наш пример, часть кода в нём подсветится жёлтым. Можно нажать Option + Enter [Alt + Enter], выделив этот код, и вам будет предложено сделать этот член package-private.
Постарайтесь думать о вложенных классах как о соседних, а не дочерних. Вы не можете добраться до приватного члена другого класса. Нужно сделать их видимыми в пределах пакета. Даже в библиотеке это не должно навредить инкапсуляции: скорее всего, никто не будет класть свои классы в один пакет с библиотечными. Если вы обнаружили синтетические аксессоры в библиотеке, стоит отправить feature request разработчикам. По-хорошему, в будущем библиотека не должна собираться, если в ней найдутся такие методы.
Я перебирал кучи открытых библиотек и исправлял эти проблемы видимости, чтобы библиотеки не создавали сотни этих методов. Это категорически важно для библиотек, которые занимаются кодогенерацией. Нам удалось убрать 2 700 методов из нашего приложения, изменив один из шагов кодогенерации. 2 700 методов просто так, за генерацию того, что должно иметь доступ в пределах пакета вместо приватного.
Синтетические методы
Синтетические методы так называются, потому что мы не пишем их. Они генерируются автоматически. Аксессоры — не единственный вид синтетических методов. Дженерики, как и вложенные классы, появились после Java 1.0, и нужно было компилировать код так, чтобы сохранить совместимость с предыдущими версиями байт-кода.
// Callbacks.java
interface Callback<T> {
void call(T value);
}
class StringCallback implements Callback<String> {
@Override public void call(String value) {
System.out.println(value);
}
}Такое часто можно увидеть в библиотеках и приложениях. Мы используем эти интерфейсы с дженериками, потому что это очень удобно и при этом типобезопасно.
$ javac Callbacks.java
$ javap StringCallback
class StringCallback implements Callback<java.lang.String> {
StringCallback();
public void call(java.lang.String);
public void call(java.lang.Object);
}
Метод, который принимает значение generic-типа, при компиляции превращается в два метода. В этом примере один принимает строку, то есть тот тип, который указан, а второй, bridge-метод, принимает просто Object. Это называется принципом стирания. Если вы слышали о стирании типов, но не понимали, что происходит, то вот как раз пример стирания. Компилятор генерирует код, который использует Object, потому что именно этот тип остаётся после стирания.
$ javap -c StringCallback
class StringCallback implements Callback<java.lang.String> {
StringCallback();
Code: <removed>
public void call(java.lang.String);
Code: <removed>
public void call(java.lang.Object);
Code:
0: aload_0
1: aload_1
2: checkcast #4 // class java/lang/String
5: invokevirtual #5 // Method call:(Ljava/lang/String;)V
8: return
}
Если посмотреть, что за код в этом методе, там будет всего лишь приведение типа. Он приводит аргумент к нужному типу и передаёт его фактической реализации. Каждый generic-метод превращается в два метода.
Это касается и возвращаемых значений. Если метод возвращает generic, происходит то же самое.
// Providers.java
interface Provider<T> {
T get(Context context);
}
class ViewProvider implements Provider<View> {
@Override public View get(Context context) {
return new View(context);
}
}$ javac -bootclasspath android-sdk/platforms/android-24/android.jar \
Example.java
$ javap -c ViewProvider
class ViewProvider implements Provider<android.view.View> {
ViewProvider();
Code: <removed>
public android.view.View get(android.content.Context);
Code: <removed>
public java.lang.Object get(android.content.Context);
Code:
0: aload_0
1: aload_1
2: invokevirtual #4 // Method get:(…)Landroid/view/View;
5: areturn
}
Сгенерировалось два метода. В нашем случае один возвращает View, второй — Object. Этот метод проще, здесь нет checkcast. Он просто вызывает другой метод и возвращает возвращённый им View.
Ещё один интересный момент, который не все понимают, — это вот эта возможность языка:
class ViewProvider implements Provider<View> {
@Override public View get(Context context) {
return new View(context);
}
}
class TextViewProvider extends ViewProvider {
@Override public TextView get(Context context) {
return new TextView(context);
}
}При переопределении метода можно изменить возвращаемое значение на подтип этого типа. Это называется ковариантным возвращаемым типом. Даже не обязательно для этого реализовывать интерфейс, как в примере выше. Достаточно просто переопределить метод суперкласса. И можно изменить тип возвращаемого значения на более конкретный.
Так делают, потому что, вызвав такой метод, можно сразу получить объект нужного типа без необходимости явно приводить тип. В данном случае вместо широкого типа View метод возвращает более конкретный TextView.
Ковариантное возвращаемое значение
Уверен, вы угадаете, что здесь произойдёт.
$ javap TextViewProvider
class TextViewProvider extends ViewProvider {
TextViewProvider();
public android.widget.TextView get(android.content.Context);
public android.view.View get(android.content.Context);
public java.lang.Object get(android.content.Context);
}
Мы получаем ещё один метод. Здесь и дженерик, и ковариантный тип возвращаемого значения. Мы взяли один метод и превратили его в три, практически ничего не сделав. Вот скрипт на питоне, который их находит:
#!/usr/bin/python
import os
import subprocess
import sys
list = subprocess.check_output(["dex-method-list", sys.argv[1]])
class_info_by_name = {}
for item in list.split('\n'):
first_space = item.find(' ')
open_paren = item.find('(')
close_paren = item.find(')')
last_space = item.rfind(' ')
class_name = item[0:first_space]
method_name = item[first_space + 1:open_paren]
params = [param for param in item[open_paren + 1:close_paren].split(', ') if len(param) > 0]
return_type = item[last_space + 1:]
if last_space < close_paren:
return_type = 'void'
# print class_name, method_name, params, return_type
if class_name not in class_info_by_name:
class_info_by_name[class_name] = {}
class_info = class_info_by_name[class_name]
if method_name not in class_info:
class_info[method_name] = []
method_info_by_name = class_info[method_name]
method_info_by_name.append({
'params': params,
'return': return_type
})
count = 0
for class_name, class_info in class_info_by_name.items():
for method_name, method_info_by_name in class_info.items():
for method_info in method_info_by_name:
for other_method_info in method_info_by_name:
if method_info == other_method_info:
continue # Do not compare against self.
params = method_info['params']
other_params = other_method_info['params']
if len(params) != len(other_params):
continue # Do not compare different numbered parameter lists.
match = True
erased = False
for idx, param in enumerate(params):
other_param = other_params[idx]
if param != 'Object' and not param[0].islower() and other_param == 'Object':
erased = True
elif param != other_param:
match = False
return_type = method_info['return']
other_return_type = other_method_info['return']
if return_type != 'Object' and other_return_type == 'Object':
erased = True
elif return_type != other_return_type:
match = False
if match and erased:
count += 1
# print "FOUND! %s %s %s %s" % (class_name, method_name, params, return_type)
# print " %s %s %s %s" % (class_name, method_name, other_params, other_return_type)
print os.path.basename(sys.argv[1]) + '\t' + str(count)
Этот код будет выполняться довольно долго, но мне было интересно, насколько часто такое встречается в приложениях. Теперь запустим этот скрипт и пропустим через него каждое приложение, установленное на моём телефоне.
$ column -t -s $'\t' \
<(echo -e "NAME\tERASED" \
&& find apks -type f | \
xargs -L1 ./erased.py | \
sort -k2,2nr)
Их всего несколько тысяч. И с ними мало что можно сделать. Как я показал, ProGuard может помочь здесь: если он обнаружит, что generic-версия метода (того, что принимает и/или возвращает Object), не используется, ProGuard удалит его, сотни и тысячи их будут удалены ProGuard'ом. Но какие-то из них — нет, потому что они используются в generic-смысле, когда метод вызывается на интерфейсе.
[А у меня есть способ борьбы с bridge-методами, но он вам не понравится: стереть типы руками. Если вместо str -> System.out.println(str) написать (Callback<String>) (Callback) str -> System.out.println((String) str), семантика не изменится, а bridge-методы пропадут. ]
Последний пример, связанный с методами, — о языковых конструкциях Java 8 в Android.
У нас давно есть Retrolambda. Но теперь также существует компилятор Jack, который занимается тем же самым, с сохранением обратной совместимости. Но есть ли накладные расходы, связанные с языковыми конструкциями Java 8?
Вот простой класс, который говорит Hi, если вызвать его метод. Я хочу, чтобы Greeter поздоровался последством Executor. У Executor единственный метод run [на самом деле — execute], который принимает Runnable. В Java 7 мы должны сделать локальную переменную типа Greeter финальной. Потом мы создадим новый Runnable и вызовем этот метод.
class Greeter {
void sayHi() {
System.out.println("Hi!");
}
}
class Example {
public static void main(String... args) {
Executor executor = Executors.newSingleThreadExecutor();
final Greeter greeter = new Greeter();
executor.execute(new Runnable() {
@Override public void run() {
greeter.sayHi();
}
});
}
}В Java 8 всё это менее многословно. Здесь всё так же создаётся Runnable, но это происходит неявно. Нам не нужно задавать тип возвращаемого значения, имя метода и типы аргументов:
class Greeter {
void sayHi() {
System.out.println("Hi!");
}
}
class Example {
public static void main(String... args) {
Executor executor = Executors.newSingleThreadExecutor();
Greeter greeter = new Greeter();
executor.execute(() -> greeter.sayHi());
}
}Ещё есть указатели на методы. Они интереснее, потому что компилятор самостоятельно может додуматься, что, если метод не принимает аргументов и ничего не возвращает, его можно рассматривать как Runnable.
class Greeter {
void sayHi() {
System.out.println("Hi!");
}
}
class Example {
public static void main(String... args) {
Executor executor = Executors.newSingleThreadExecutor();
Greeter greeter = new Greeter();
executor.execute(greeter::sayHi);
}
}Сколько это стоит?
Это всё забавно, но сколько это стоит? В какую цену нам обходится использование этих конструкций языка? Я использовал цепочку инструментов, работающую с Retrolambda, и цепочку, работающую с Jack.
Retrolambda toolchain
$ javac *.java
$ java -Dretrolambda.inputDir=. -Dretrolambda.classpath=. \
-jar retrolambda.jar
$ dx --dex --output=example.dex *.class
$ dex-method-list example.dex
Jack toolchain
$ java -jar android-sdk/build-tools/24.0.1/jack.jar \
-cp android-sdk/platforms/android-24/android.jar \
--output-dex . *.java
$ dex-method-list classes.dex
Здесь не используется ни ProGuard, ни минимизация средствами Jack, которые могли бы повлиять на результат. В случае с анонимными классами, которыми мы пользовались так долго, всегда генерируется два метода.
Example$1 <init>(Greeter)
Example$1 run()
$ javap -c 'Example$1'
final class Example$1 implements java.lang.Runnable {
Example$1(Greeter);
Code: <removed>
public void run();
Code:
0: aload_0
1: getfield #1 // Field val$greeter:LGreeter;
4: invokevirtual #3 // Method Greeter.sayHi:()V
7: return
}
Скомпилируем и декомпилируем наш класс. Здесь есть конструктор, который принимает Greeter, и метод run, который вызывает метод sayHi. Это непосредственно то, что мы ожидали увидеть, очень просто и прямолинейно.
Использовать лямбды со старой версией Retrolambda очень дорого. Из-за одной строки кода создаётся шесть-семь методов. Благо, в актуальной версии — четыре. Jack генерирует три, всего на один больше, чем анонимный класс. Но в чём разница? Зачем этот лишний метод?
Сейчас разберёмся. Вот Retrolambda со своими двумя лишними методами:
Example lambda$main$0(Greeter)
Example$$Lambda$1 <init>(Greeter)
Example$$Lambda$1 lambdaFactory$(Greeter) → Runnable
Example$$Lambda$1 run()
Один из новых методов — наверху. Когда объявляешь блок кода, этот код должен куда-то записаться. Он не находится в методе, в котором объявляется лямбда, потому что это было бы странно. Он не принадлежит этому методу. Он должен быть сохранён так, чтобы его можно было передать в вызываемый метод.
$ javap -c Example
class Example {
static void lambda$main$0(Greeter);
Code:
0: aload_0
1: invokespecial #45 // Method sayHi:()V
4: return
Вот зачем нужен верхний метод. Чтобы хранить написанный в лямбде код в этом же классе. Здесь видно реализацию: всё, что он делает, — вызывает метод sayHi. Так же, как делала наша реализация Runnable. Также у нас остаётся конструктор.
Естественно, остаётся метод run. Но код в нём другой:
$ javap -c 'Example$$Lambda$1'
final class Example$$Lambda$1 implements java.lang.Runnable {
public void run();
Code:
0: aload_0
1: getfield #15 // Field arg$1:LGreeter;
4: invokestatic #21 // Method Example.lambda$main$0:
7: return
}
Вместо того чтобы вызывать Greeter непосредственно, он вызывает метод lambda$main$0 на исходном классе. Вот где этот лишний метод. Вот где из-за Retrolambda грустит котик.
Example lambda$main$0(Greeter)
Example$$Lambda$1 <init>(Greeter)
Example$$Lambda$1 lambdaFactory$(Greeter) → Runnable
Example$$Lambda$1 run()
Вместо того чтобы непосредственно создавать объект этого класса вызовом конструктора, создаётся статический фабричный метод, который и вызывает этот конструктор.
Jack делает по сути то же самое, только не создаёт статическую фабрику.
Example -Example_lambda$1(Greeter) Example$-void_main_java_lang_String__args_LambdaImpl0 <init>(Greeter) Example$-void_main_java_lang_String__args_LambdaImpl0 run()
Мы тоже получаем метод с кодом лямбды и с сумасшедшим названием, а также сгенерированный класс, прямо в название которого креативно вставлен тип аргумента [внешнего метода — main(String[])]. Вот эти три метода. Из-за лямбды создаётся дополнительный метод, тот, что наверху.
Указатели на методы также очень интересны. Retrolambda и Jack ведут себя практически одинаково. С Retrolambda появляется лишний метод, если ссылаешься на приватный метод, и генерирует его не Retrolambda. Java генерирует синтетический аксессор, потому что, если передаёшь другому классу указатель на свой приватный метод, у него должна быть возможность вызвать его. Вот откуда берётся четвёртый метод.
Очень интересно, что Jack генерирует три метода для каждого указателя на метод. Он должен был бы генерировать по два, кроме этого случая с приватным методом. В этом случае он должен был бы генерировать три. Сейчас он генерирует аксессор для каждого указателя на метод. На эту тему открыт баг, так что, возможно, Jack будет генерировать по два метода. Это очень важно, потому что тогда указатели на методы будут стоить столько же, сколько и анонимные классы. То есть смена абстракции при переходе с анонимных классов на указатели на методы будет абсолютно безвозмездной.
Лямбды, к сожалению, уже, скорее всего, не подешевеют до того же уровня. Причина этого в том, что внутри лямбды может быть обращение к приватным членам класса. Такой код нельзя просто так скопировать в сгенерированный Runnable. Потому что, опять же, нет способа добраться до этих членов из другого класса.
Лямбды в дикой природе
Давайте посмотрим, как много лямбд в дикой природе. Так же, как и предыдущие скрипты, этот будет выполняться долго.
#!/bin/bash lambdas.sh
set -e
ALL=$(dex-method-list $1)
RL=$(echo "$ALL" | \grep ' lambda\$' | wc -l | xargs)
JACK=$(echo "$ALL" | \grep '_lambda\$' | wc -l | xargs)
NAME=$(basename $1)
echo -e "$NAME\t$RL\t$JACK"
$ column -t -s $'\t' \
<(echo -e "NAME\tRETROLAMBDA\tJACK" \
&& find apks -type f | \
xargs -L1 ./lambdas.sh | \
sort -k2,2nr)
NAME RETROLAMBDA JACK
com.squareup.cash 826 0
com.robinhood.android 680 0
com.imdb.mobile 306 0
com.stackexchange.marvin 174 0
com.eventbrite.attendee 53 0
com.untappdllc.app 53 0
Это заняло около 10 минут. Это также зависит от того, сколько приложений у вас на телефоне. Если решите повторить эксперимент, наберитесь терпения.
К сожалению, не так много людей использует лямбды, и я был удивлён, что у нас их больше всего. У нас 826 лямбд. Это количество лямбд, но не количество методов. Количество методов от этих лямбд — это 826, умноженное на три–четыре.
Никто ещё не использует Jack, по крайней мере, в тех приложениях, которые у меня установлены. Либо кто-то использовал Jack, но не использовал лямбды, что было бы странно. Или эти приложения обработаны ProGuard'ом.
И, опять же, ProGuard полностью прячет имена лямбда-классов и методов. Если вы — разработчик популярного приложения и используете ProGuard, видимо, поэтому вас нет в списке. Или же мне просто не нравится ваше приложение.
Это всё было о методах. Причина, по которой я раскопал это всё, — попытка отсрочить достижение предела в 65 тысяч методов. Но также вызов этих методов занимает определённое время в рантайме. Загрузка байт-кода занимает время. Лишние переходы от метода к методу дают о себе знать. Приватное поле — мой фаворит, потому что мы уже много раз видели, что происходит в анонимных listener'ах. Зачастую они запускаются в главном потоке в результате взаимодействия пользователя с интерфейсом.
Нам бы очень не хотелось запускать тяжёлый в вычислительном смысле метод в главном потоке, что бы то ни было: расчёт размеров элементов интерфейса, анимации, что угодно. Не хотелось бы делать лишних телодвижений, перепрыгивать через этот лишний метод, когда нужно просто обратиться к полю. Поиск поля происходит довольно быстро. Вызов метода вместе с поиском поля тоже происходят быстро, но всё же дольше, чем просто поиск поля, я гарантирую это. Не хотелось бы пропускать кадры только из-за того, что есть лишние, обходные, бесполезные методы, которые существуют только для того, чтобы раздувать ваш APK и понемногу замедлять приложение.
Коллекции
Хотелось бы сменить тему и поговорить о расходах в рантайме. Речь пойдёт о коллекциях.
HashMap<K, V>
HashSet<E>
HashMap<Integer, V>
HashMap<Boolean>
HashMap<Integer, Integer>
HashMap<Integer, Long>
HashMap<Long, V>ArrayMap<K, V>
ArraySet<E>
SparseArray<V>
SparseBooleanArray
SparseIntArray
SparseLongArray
LongSparseArray<V>Если вы используете коллекции из левой колонки, вероятно, вы расходуете больше
ресурсов памяти, чем могли бы.
Думаю, сейчас все знают о таких коллекциях. Различные реализации адаптированы для довольно распространённых частных случаев. Например, существует специальная коллекция для ситуации, когда в таблице в качестве ключей используются целые числа (int).

Эти коллекции нужны, чтобы решить проблемы боксинга примитивов. Если вы не в курсе, autoboxing — это механизм языка: например, в HashMap с целочисленными ключами мы кладём какое-то значение. Или, наоборот, пытаемся найти значение по ключу. Интовый ключ проходит через дополнительный шаг, который называется автобоксингом. Берётся примитивное значение и оборачивается в объект, в данном случае — Integer.
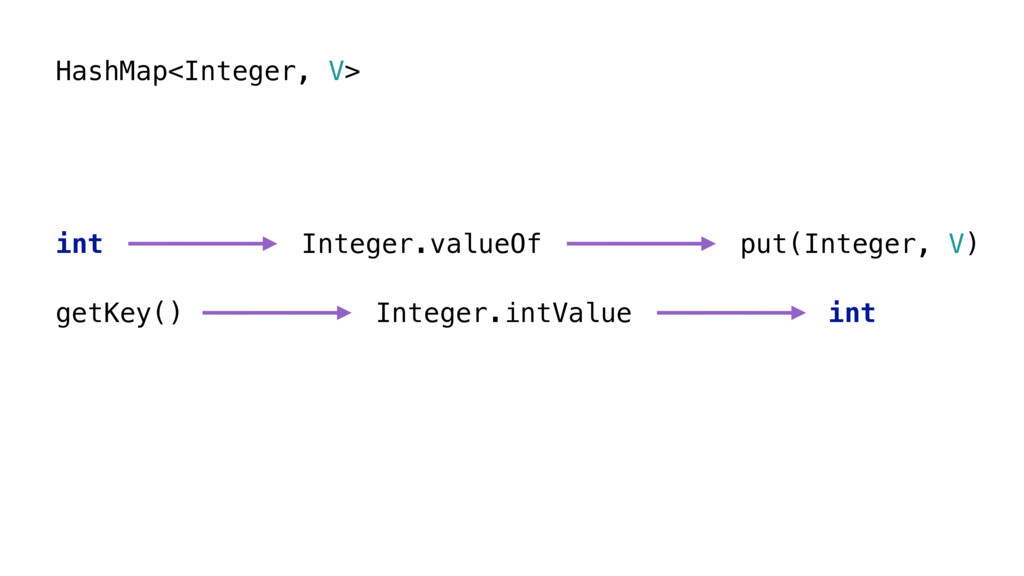
Нижнее преобразование, разворачивание, не такое уж и дорогое. Верхний вариант похуже. Для небольших чисел это не так уж и плохо, но если у вас гора разных чисел, то каждый раз при вызове метода, принимающего дженерик, будет создаваться новый объект. [Java хранит Integer'ы в диапазоне [-128; 127] в пуле. Если бы был выбран больший диапазон, пул занимал бы слишком много памяти. Это компромисс между потреблением памяти и скоростью выполнения.]
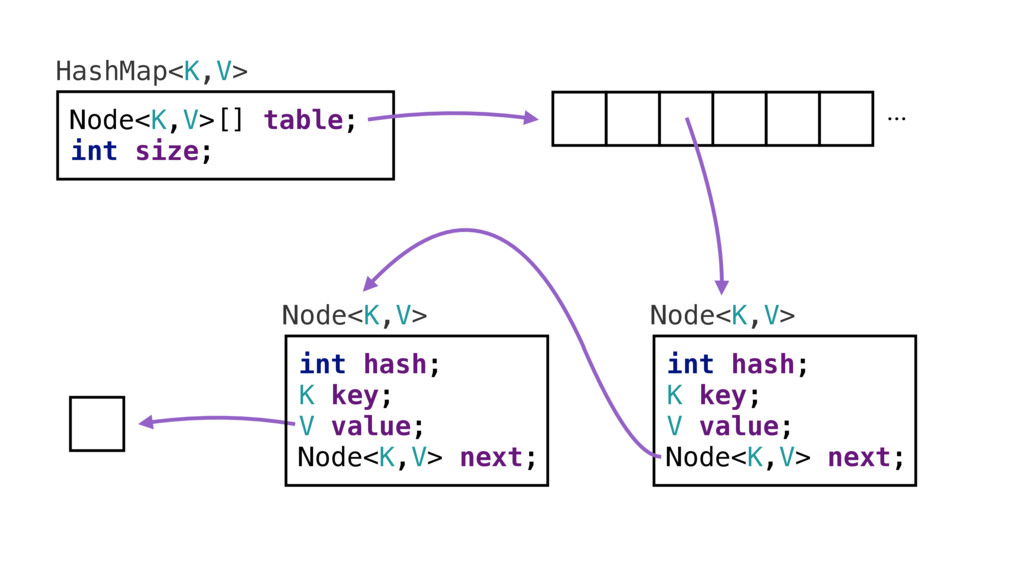
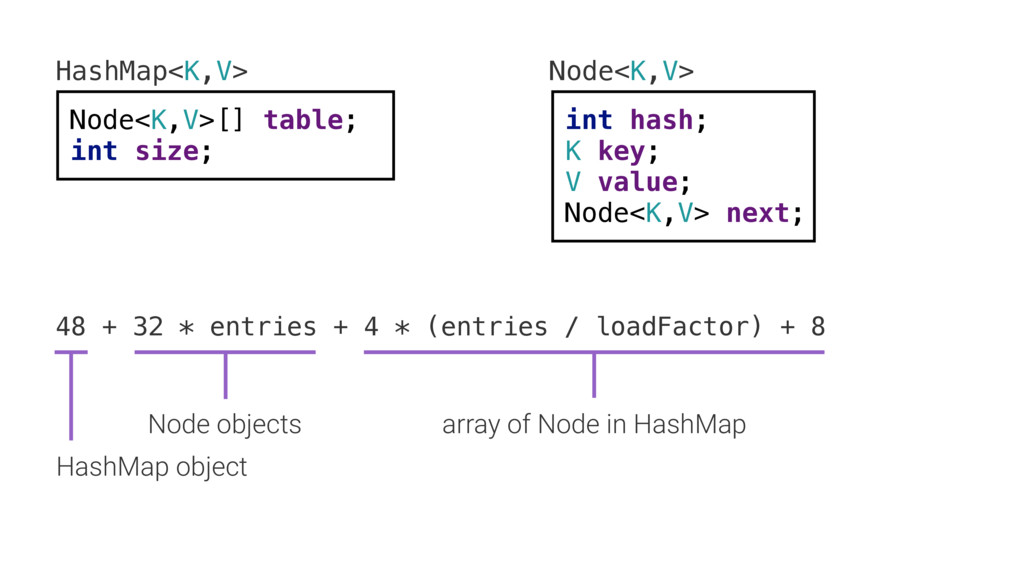
Первое — это опосредованный путь информации. Если посмотреть на реализацию HashMap, там есть массив «узлов». Когда добавляешь или ищешь значение, происходит поиск в этом массиве. Происходит хеширование, которое показывает, в каком месте в этом массиве должно лежать значение. Это делается за фиксированное количество времени [т. е. O(1)].
Узел — это пара ключ/значение. Также там хранится хэш и указатель на следующий узел. Допустим, при поиске мы нашли нужную ячейку в массиве и добрались до узла. Теперь мы хотим заглянуть в ячейку и получить значение. В итоге мы получаем указатель на значение. Приходится пройти через все эти перенаправления. Все эти объекты находятся в разных адресах памяти. Нужно совершить все эти переходы, чтобы получить значение, соответствующее ключу. Или положить значение, соответствующее ключу. Но бывает и хуже.
Иногда возникают коллизии хэшей: когда два узла оказываются в одной хэш-корзине, хэш-таблица создаёт односвязный список в этой корзине. Если нас угораздит попасть в такую ситуацию, понадобится пройти по списку и найти точное совпадение хэша. [HashMap намеренно уменьшает диапазон хэша. hashCode() возвращает значение из всего диапазона integer, а HashMap должно поместить его в диапазон [0; table.length-1], вначале это [0; 7], и такие хэши, конечно, часто сталкиваются. Но и обычные хэши сталкиваются, поэтому кроме a.hashCode() == b.hashCode() выполняется проверка a.equals(b).]
Я хотел бы также рассмотреть SparseArray. Это замена для HashMap<Integer, V>. Мы обязательно это сделаем, но сначала я посчитаю накладные расходы хэш-таблицы в памяти. Тут у нас два класса.
$ java -jar jol-cli-0.5-full.jar internals java.util.HashMap
# Running 64-bit HotSpot VM.
# Objects are 8 bytes aligned.
java.util.HashMap object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00
4 4 (object header) 00 00 00 00
8 4 (object header) 9f 37 00 f8
12 4 Set AbstractMap.keySet null
16 4 Collection AbstractMap.values null
20 4 int HashMap.size 0
24 4 int HashMap.modCount 0
28 4 int HashMap.threshold 0
32 4 float HashMap.loadFactor 0.75
36 4 Node[] HashMap.table null
40 4 Set HashMap.entrySet null
44 4 (loss due to the next object alignment)
Instance size: 48 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
Мы воспользуемся инструментом, который называется Java Object Layout, он расскажет, сколько стоит создание такого объекта в памяти. Будучи запущенным на HashMap, он выведет много разной информации. Покажет стоимость каждого поля. Внизу важное число, показывающее размер каждого экземпляра HashMap, просто HashMap, без узлов, ключей, значений. Сам по себе HashMap занимает 48 байт. Это не так уж плохо. Это немного.
$ java -jar jol-cli-0.5-full.jar internals 'java.util.HashMap$Node'
# Running 64-bit HotSpot VM.
# Objects are 8 bytes aligned.
java.util.HashMap$Node object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 12 (object header) N/A
12 4 int Node.hash N/A
16 4 Object Node.key N/A
20 4 Object Node.value N/A
24 4 Node Node.next N/A
28 4 (loss due to the next object alignment)
Instance size: 32 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
Теперь сделаем то же самое с Node, классом узла. Видим четыре поля. Объект занимает 32 байта. По 32 байта на каждый узел map'а. Каждый элемент map'а, каждая пара ключ/значение. Это 32 байта, умноженные на количество пар имя/значение.
Можно использовать такую формулу, чтобы определить фактический размер объекта в куче, когда в нём уже есть значения.
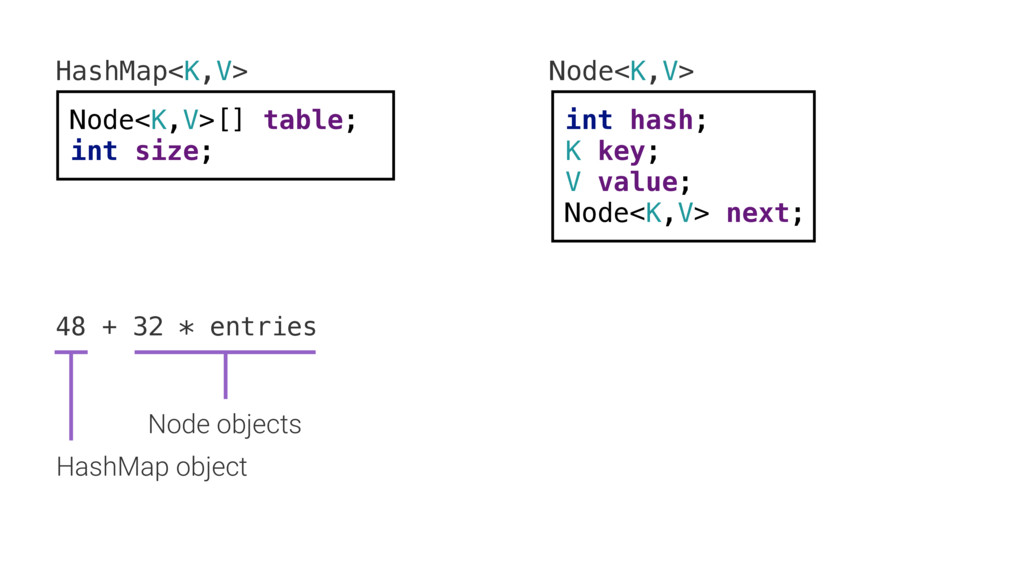
Это не совсем верно. Нужно учесть ещё массив, в котором хранятся узлы, так что мы посчитаем, сколько места он занимает. Это сложнее. Четыре байта (один integer), указатель на элемент массива, умноженный на размер элемента массива. [В 64-битных виртуальных машинах без сжатых указателей, соответственно, по 8 байт. Но это актуально только для куч размером больше 32 ГиБ, в Android такой роскоши нет.]
Проблема в том, что у хэш-таблицы есть параметр, называемый степенью загрузки (load factor). HashMap старается не быть загруженной по полной. Она поддерживает определённую степень загрузки и, достигая определённого порога, выделяет больший массив, как это сделал бы ArrayList.
Причина в том, что, если этого не произойдёт, будет очень много коллизий, много длинных односвязных списков и большая потеря производительности. Так, фактический объём хэш-таблицы зависит от количества пар ключ/значение и степени загрузки. Разберёмся, сколько он займёт в памяти. Кстати, степень загрузки по умолчанию — 75%. HashMap всегда старается быть заполненной на 3/4.
SparseArray (дословно — разреженный массив) — это коллекция, призванная заменить хэш-таблицы с целочисленными ключами. Давайте посмотрим на те же два фактора, что и в HashMap: на уровень непрямолинейности поиска/записи и на объём занимаемой памяти. SparseArray хранит два массива: один — это ключи, второй — значения. Когда пишешь значения в эту коллекцию или читаешь из неё, первое, что происходит, — это поиск в массиве ключей, и, в отличие от HashMap, это не делается фиксированное количество времени. Происходит бинарный поиск по массиву. [Сложность бинарного поиска (Arrays.binarySearch()) — O(log n), прыжка в хэш-корзину — O(1); но на практике HashMap оказывается быстрее только на очень больших таблицах.] Так мы попадаем в массив значений, и в этом случае бинарный поиск точно показывает ячейку со значением. Теперь это значение берётся из массива и возвращается вам. [У HashMap ещё присутствовал этап с односвязным списком, где поиск мог длиться вплоть до O(n), где n — количество узлов в одной корзине.]
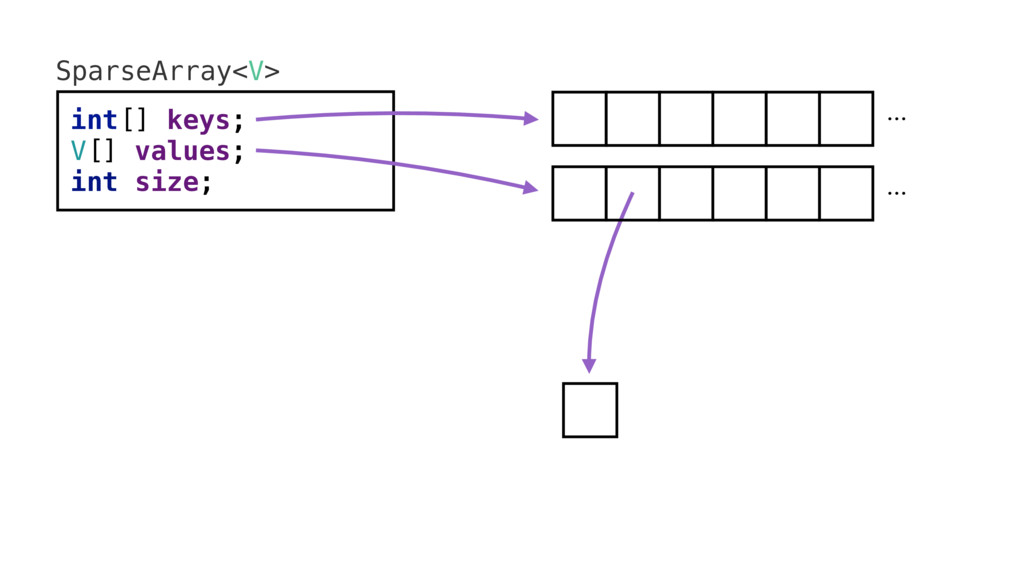
Здесь гораздо меньше путешествий по памяти. Целочисленный массив непрерывен, нет односвязных списков. Найдя ключ, можно перейти непосредственно к нужному значению. Нет узлов, которые нужно разворачивать, чтобы добираться до значений. Путь гораздо более прямой. Однако нужно учитывать, что бинарный поиск происходит не мгновенно. Поэтому разреженный массив хорош для относительно маленьких таблиц. Под маленькими я подразумеваю таблицы размером в сотни пар ключ/значение. Если добраться до тысяч, скорость бинарного поиска уменьшится, и HashMap будет привлекательнее в плане скорости. [В Android мне не приходилось иметь дело с таблицами размером в тысячи пар ключ/значение. Это больше похоже на задачу для сервера (кэши). Если вы встретите такое, лучше возьмите какую-нибудь специализированную реализацию HashMap — см. Trove, Guava.]
$ javac SparseArray.java
$ java -cp .:jol-cli-0.5-full.jar org.openjdk.jol.Main \
internals android.util.SparseArray
# Running 64-bit HotSpot VM.
# Objects are 8 bytes aligned.
android.util.SparseArray object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00
4 4 (object header) 00 00 00 00
8 4 (object header) 1a 69 01 f8
12 4 int SparseArray.mSize 0
16 1 boolean SparseArray.mGarbage false
17 3 (alignment/padding gap) N/A
20 4 int[] SparseArray.mKeys [0, 0, 0, 0, 0, 0, …]
24 4 Object[] SparseArray.mValues [null, null, null, …]
28 4 (loss due to the next object alignment)
Instance size: 32 bytes
Space losses: 3 bytes internal + 4 bytes external = 7 bytes total
В этом случае, т. к. классы те же, а JVM 64-битная, и Android теперь 64-битный, числа должны быть очень близкими к действительности. Если вас сильно волнует точность вычислений, допускайте расхождение порядка 20%. Это гораздо проще, чем выяснить размер объекта в Android. Это, конечно, возможно, но так гораздо проще.
Сам по себе SparseArray немного легче, 32 байта. Этот объём не имеет большого значения. Значение имеет объём, занимаемый каждой записью. Нужно посчитать объём массива целочисленных ключей: это четыре (размер указателя), умноженное на количество записей, плюс восемь (размер заголовка массива). И есть массив значений, который так же точно занимает по четыре байта на каждую запись плюс ещё восемь байт.
Разница ещё и в том, что у SparseArray нет явного коэффициента загруженности,
но похожий эффект присутствует, потому
что массив — это бинарное дерево. Он не заполненный до предела, не сплошной. Есть незанятые промежутки. Нужно
принимать во внимание этот коэффициент, и он будет близок к коэффициенту загрузки. Он зависит от того, какие
конкретно данные будут положены в таблицу. Я буду использовать то же значение: предположу, что массив заполнен
на 75%, что вполне правдоподобно.
[Между элементами SparseArray промежутков обычно нет. Они появляются, когда из SparseArray удаляют пару
имя/значение, но такое состояние кратковременно: очень скоро «мусор» собирается и промежутки исчезают. Пустые
ячейки массивов остаются только в конце, в качестве запаса, как у ArrayList. Тем не менее, взятый Джейком
коэффициент правдоподобен. Для SparseArrayCompat он составляет 0.82 при 50 элементах и 0.69 в
диапазоне 20..50 элементов. SparseArray каждый раз растёт вдвое, поэтому там коэффициент должен
быть очень близок к 0.75.]
SparseArray<V>32 + (4×entries + 4×entries) / 0.7532 + (8 + 4×entries + 8 + 4×entries) / 0.75 32 — размер объекта SparseArray; 8 — заголовок массива, 4 — размер элемента массива; массивов два HashMap<Integer, V> 48 + 32×entries + 4×(entries/loadFactor) + 8
Теперь можно непосредственно сравнить, сколько места занимают рассмотренные коллекции. Опять же, я буду использовать степень загрузки хэш-таблицы по умолчанию, 0,75. Нужно также выбрать количество записей в таблице. Я выбрал 50. Пусть это таблица штатов в США. Теперь нужно произвести вычисления.
SparseArray<V>32 + (4×50 + 4×50) / 0.75 = 656Там не учтены размеры заголовков массивов (по 8 байт), а результат арифметических вычислений на самом деле — 565.
32 + (8 + 4×50 + 8 + 4×50) / 0.75 = 586 HashMap<Integer, V> 48 + 32×50 + 4×(50/0.75) + 8 = 1922
Как видим, разреженный массив втрое легче хэш-таблицы. Стоит помнить, что у SparseArray есть просадка производительности, потому что бинарный поиск происходит не мгновенно. В случае с 50 элементами бинарный поиск произойдёт очень быстро. [Если быть точным, бинарный поиск по массиву из 33..64 элементов занимает максимум шесть шагов, что сравнимо с поиском в хэш-таблице.]
Заключение
Мы рассмотрели много всего. Оказалось, что можно применить некоторые предельно простые оптимизации, которые помогут минимизировать эти накладные расходы что при компиляции, с методами, что в рантайме, и упростить путь, который проходит информация.
Первое я уже показал: включите инспекцию, которая поможет найти обращения к приватным членам вложенного/внешнего класса. Не игнорируйте это. Не нужно проходиться по всем классам и сразу всё это править. Это можно делать постепенно, с теми классами, которые вы пишете или правите. И, конечно, для библиотек это более важно.
Разработчику библиотеки стоит минимизировать воздействие и на размер APK, и на производительность и потребление памяти. Если вы — автор библиотеки, возможно, стоит пройтись по всем классам и найти всё это. Синтетическим аксессорам нет причин существовать, тем более — в библиотеках. Это трата места в dex-файле. Это трата времени в рантайме. Сообщайте о них как о багах.
Если вы используете Retrolambda, пожааалуйста, убедитесь, что пользуетесь последней версией, потому что вы могли бы избавиться от тысяч методов. Разработчикам библиотек, возможно, стоит смириться и работать с анонимными классами. Делов-то! [Сомнительный совет. У анонимных классов есть и обратная сторона: экземпляр создаётся при каждом выполнении кода, который его содержит. Даже если класс ничего не захватывает и одного экземпляра хватило бы на всех.] Но, опять же, это всё ради того, чтобы минимально влиять на приложения, в которых используется библиотека, и не приносить проблем разработчикам приложений.
Попробуйте Jack. Это стоит того. Он всё ещё в стадии разработки. Там не хватает определённых необходимых некоторым
разработчикам вещей, но простым приложениям, которые не делают ничего особеннго во время сборки, он должен
подойти. [Всё, от идеи разрабатывать Jack отказались. Цепочка инструментов осталась неизменной.]
Не игнорируйте баги. Обнаружив, что Jack падает, не надо говорить: «А, ладно, попробую через два года». Хотя бы сообщите о баге перед тем, как вернуться к javac. Это будущее, можно закрыть глаза и уши, но это происходит. Лучше найти эти баги раньше, чем позже. Затем просто включите ProGuard. Он поможет вам. Хоть ProGuard, хоть новый инкрементальный скукоживатель кода, который работает в Instant run и, вероятно, будет использоваться вместе с Jack в будущем.
Не нужно использовать с ProGuard правила, под которые подпадает слишком много классов. Если увидите ** в файле правил ProGuard, знайте: это 100% неправильно. Не нужно так делать, иначе преимущества, получаемые от использования ProGuard, просто исчезают. Этим вы говорите: «Я добавил OkHttp, но мне не нужны методы для работы с HTTP/2, которые я не использую. Я не хочу, чтобы они были удалены. Пусть остаются». Это тупо. Если найдёте такое в открытых библиотеках, это баг. Сообщите об этом разработчикам. Если найдёте такое в своём приложении, разберитесь, как оно туда попало. Уберите эти правила, посмотрите, на что более конкретное их можно исправить.
Рекомендую также другие презентации на тему производительности и DEX.